Big Data com Hadoop: Processamento de Dados em Grande Escala

I am Backend Developer at Banco do Brasil,
Com a crescente geração e disponibilidade de grandes volumes de dados, a necessidade de soluções eficientes para lidar com o processamento e análise de Big Data se tornou imperativa. Nesse contexto, o Apache Hadoop se destaca como uma das principais tecnologias para o processamento de Big Data, oferecendo escalabilidade, tolerância a falhas e recursos avançados para lidar com enormes conjuntos de dados. Nesse artigo, pretendo fazer uma breve apresentação dessa ferramenta. Mas primeiro, o que é essa tão famosa Big Data?
O que é Big data?
Big Data consiste em um conjunto de dados maior e mais complexo, especialmente originado de novas fontes de dados, como históricos de serviços, conteúdo de redes sociais, fluxos de cliques em uma página da web, dentre diversas outras. Esse grande volume de dados é usado para resolver problemas de negócios anteriormente insolúveis.
O que é o Apache Hadoop?
Como uma proposta para superar os desafios do processamento de grandes quantidades de dados, surge o Apache Hadoop, um framework que permite lidar com volumes massivos e complexos de informações provenientes de diversas fontes. O Hadoop simplifica a gestão desses conjuntos de dados, que são tão vastos que as ferramentas tradicionais de processamento não conseguem lidar com eles de forma eficiente. Com o Hadoop, problemas como integridade dos dados, disponibilidade dos nós, escalabilidade das aplicações e recuperação de falhas são simplificados para os desenvolvedores. A existência de frameworks de código aberto, como o Hadoop e o Spark, têm sido fundamental para impulsionar o crescimento do big data, tornando o trabalho com essa abundância de dados mais acessível e econômico em termos de armazenamento.
Arquitetura e componentes do Hadoop
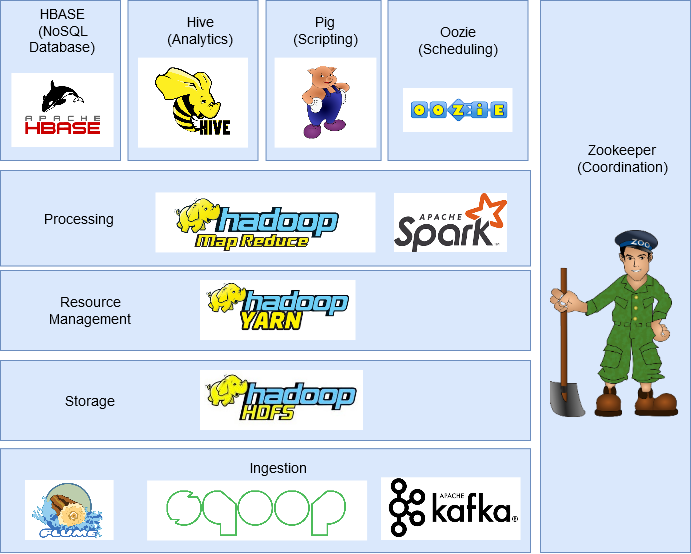
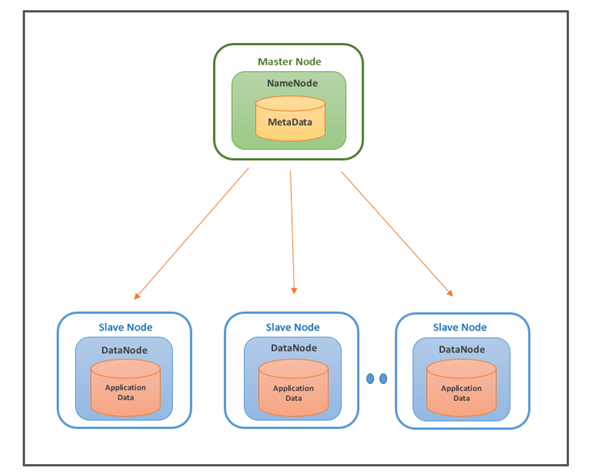
HDFS: o sistema de arquivos distribuídos do Hadoop
No HDFS, os dados são divididos em blocos de tamanho fixo e cada bloco é replicado em vários nós do cluster. Essa replicação dos dados tem o objetivo de garantir a redundância e a recuperação de falhas. A divisão dos dados em blocos permite que o processamento seja paralelizado e distribuído entre os nós do cluster. O HDFS possui uma arquitetura mestre-escravo. O nó mestre, chamado NameNode, é responsável pelo gerenciamento dos metadados do sistema de arquivos, como informações sobre a localização dos blocos de dados e permissões de acesso. Os nós escravos, chamados DataNodes, são responsáveis pelo armazenamento e recuperação dos blocos de dados.
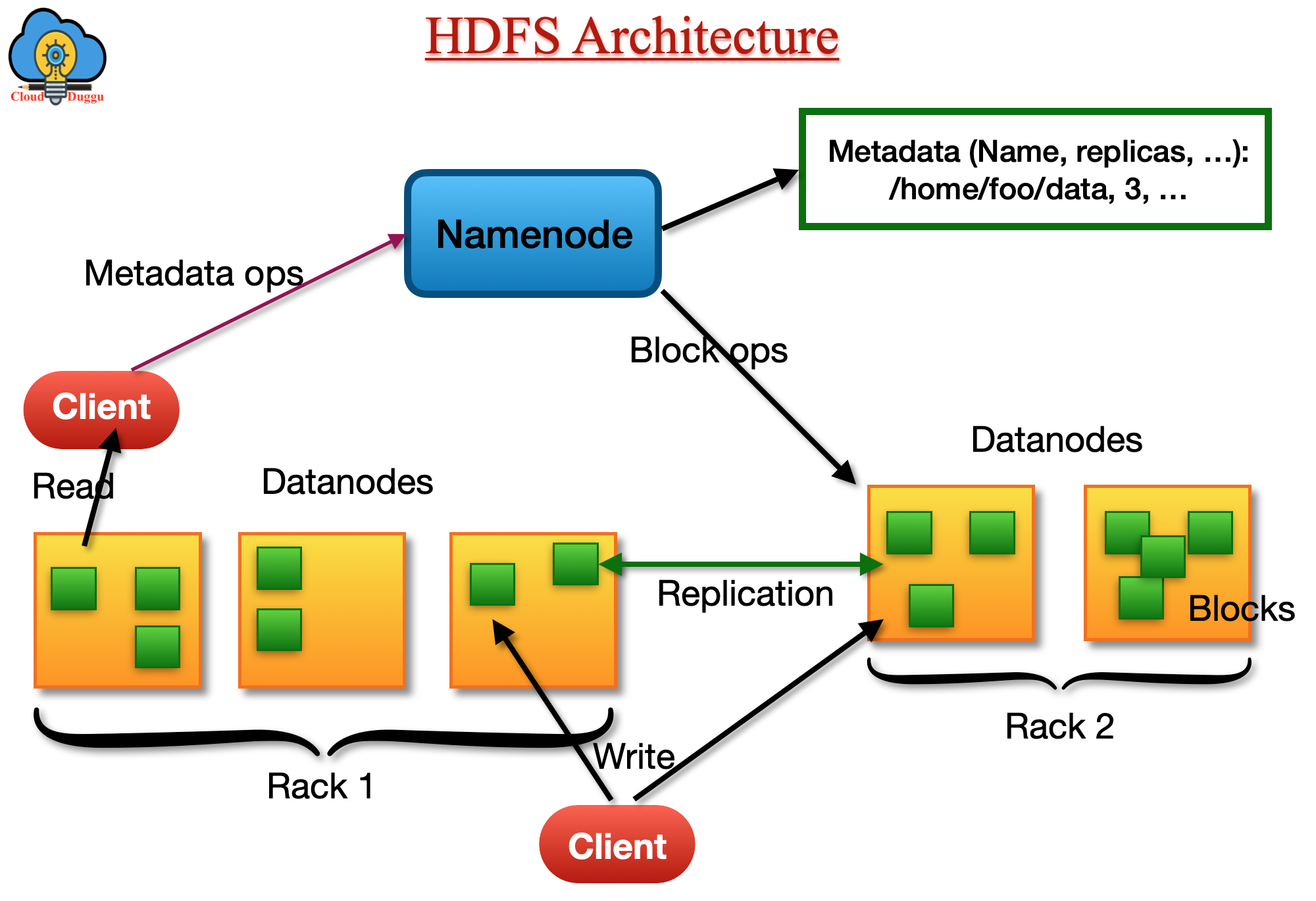
Quando um arquivo é enviado para o HDFS,inicialmente, o arquivo é guardado localmente em um arquivo temporário. À medida que o arquivo vai crescendo e atinge o tamanho definido para um bloco HDFS (geralmente 128MB na versão 2.0 do Hadoop e 64MB na versão 1.0), ocorre a interação com o NameNode, que retorna ao cliente uma lista com a identificação dos DataNodes onde o bloco deverá ser armazenado. O cliente, então, transfere os dados diretamente para os DataNodes da lista, dando início ao processo de replicação. O HDFS geralmente adota um fator de replicação igual a 3, o que significa que cada bloco será replicado em três DataNodes diferentes para garantir a redundância e a tolerância a falhas. É importante ressaltar que, mesmo que o processo de replicação de milhares de blocos ocorra paralelamente, a replicação de cada bloco, ou seja, a cópia do bloco de dados desde o primeiro até o último DataNode, é sequencial. Durante a leitura dos dados armazenados no HDFS, o cliente interage novamente com o NameNode para obter informações sobre a localização dos blocos de dados. Com base nessas informações, o cliente pode buscar diretamente os blocos de dados nos DataNodes onde estão armazenados. O HDFS é otimizado para leituras sequenciais, o que o torna adequado para aplicações de processamento em lote, onde é comum a necessidade de acessar grandes volumes de dados de forma sequencial.
MapReduce: o paradigma de programação do Hadoop
Uma das principais características do Hadoop é o paradigma de programação MapReduce, que permite processar dados em paralelo em um cluster de computadores. O paradigma MapReduce divide o processamento em duas etapas principais: o mapeamento (map) e a redução (reduce). Na etapa de mapeamento, os dados são divididos em pares chave-valor e passados por uma função de mapeamento definida pelo desenvolvedor. Essa função é aplicada a cada par chave-valor individualmente, gerando uma lista intermediária de pares chave-valor. Em seguida, na etapa de redução, os pares chave-valor intermediários são agrupados pela chave e passados por uma função de redução. Essa função pode executar várias operações, como soma, contagem, média, entre outras, sobre os valores correspondentes à mesma chave. O resultado final do processo MapReduce é uma lista de pares chave-valor resultante das operações de redução.

O modelo MapReduce oferece uma abordagem poderosa e escalável para o processamento de grandes conjuntos de dados. Ele permite que desenvolvedores escrevam código simples e expressivo para realizar tarefas de processamento distribuído sem se preocupar com os detalhes de gerenciamento de clusters.
Hive: processamento de dados em linguagem SQL
O Hive é uma ferramenta do ecossistema Hadoop que permite processar dados por meio de consultas na linguagem SQL (Structured Query Language). Ele fornece uma camada de abstração que permite aos usuários executarem consultas semelhantes a SQL em grandes conjuntos de dados armazenados no Hadoop Distributed File System (HDFS). O Hive traduz essas consultas em tarefas MapReduce, permitindo que os usuários aproveitem a capacidade de processamento distribuído do Hadoop. O Hive é especialmente útil para usuários familiarizados com SQL, fornecendo uma interface familiar para a análise de dados no Hadoop.
Pig: plataforma de análise e manipulação de dados
O Pig é outra ferramenta do ecossistema Hadoop que oferece uma plataforma de alto nível para a análise e manipulação de dados. Ele fornece uma linguagem de script chamada Pig Latin, que é projetada para expressar transformações de dados de forma concisa e eficiente. O Pig Latin é compilado em tarefas MapReduce pelo Pig, permitindo o processamento distribuído de grandes volumes de dados no Hadoop. O Pig é particularmente adequado para tarefas de ETL (Extração, Transformação e Carga) e para usuários que preferem uma abordagem de programação de alto nível.
Yarn: estrutura de gerenciamento de recursos
O Yarn (Yet Another Resource Negotiator) é um componente-chave do ecossistema Hadoop responsável pelo gerenciamento de recursos do cluster. Ele atua como um escalonador e agendador de tarefas, alocando recursos de computação de forma eficiente para as aplicações em execução no cluster. O Yarn permite que várias estruturas de processamento, como MapReduce e Spark, coexistam no mesmo cluster e compartilhem os recursos disponíveis de forma equilibrada. Ele também oferece suporte para recursos como isolamento de tarefas, tolerância a falhas e monitoramento do uso de recursos no cluster.
HBase: banco de dados NoSQL distribuído
O HBase é um banco de dados NoSQL distribuído, projetado para fornecer acesso aleatório rápido aos dados armazenados no Hadoop. Ele é baseado no modelo de dados de chave-valor e oferece escalabilidade horizontal, permitindo o armazenamento e a recuperação eficientes de grandes volumes de dados. O HBase é altamente escalável e tolerante a falhas, permitindo o processamento de dados em tempo real e a realização de operações de leitura e gravação de forma eficiente.
Sqoop: integração entre o Hadoop e bancos de dados relacionais
O Sqoop é uma ferramenta do ecossistema Hadoop projetada para facilitar a integração entre o Hadoop e bancos de dados relacionais. Ele permite importar dados de bancos de dados relacionais para o Hadoop e exportar dados do Hadoop para bancos de dados relacionais. O Sqoop suporta várias fontes de dados, como MySQL, Oracle, SQL Server, entre outros, e fornece uma maneira conveniente de transferir dados entre esses sistemas e o Hadoop. Ele ajuda a simplificar o processo de ingestão de dados no Hadoop, permitindo que os usuários aproveitem os recursos de processamento distribuído do Hadoop em conjunto com seus sistemas de banco de dados existentes.
Flume: ingestão de dados em tempo real
O Flume é um componente do ecossistema Hadoop projetado para facilitar a ingestão de dados em tempo real no Hadoop. Ele fornece uma arquitetura escalável e confiável para coletar, agregar e mover grandes volumes de dados em tempo real. O Flume suporta várias fontes de dados, como logs de servidores, feeds RSS, streams de redes sociais, entre outros, e permite o envio desses dados para o Hadoop para processamento posterior. Ele é particularmente útil para casos de uso que exigem a ingestão contínua e em tempo real de dados, como monitoramento de logs ou análise de dados de fluxo.
Kafka: plataforma de streaming distribuído
O Kafka é uma plataforma de streaming distribuído que fornece uma solução escalável para a ingestão, armazenamento e processamento de fluxos contínuos de dados em tempo real. Ele permite que os usuários publiquem e assinem fluxos de dados, garantindo a entrega confiável e eficiente dos dados em um ambiente distribuído. O Kafka é amplamente utilizado para casos de uso de streaming em tempo real, como análise de dados em tempo real, monitoramento de eventos e processamento de mensagens em larga escala.
Oozie: sistema de agendamento e fluxo de trabalho
O Oozie é um sistema de agendamento e fluxo de trabalho do ecossistema Hadoop. Ele permite que os usuários definam e executem fluxos de trabalho complexos que envolvem várias etapas e dependências. O Oozie oferece suporte a várias ações, como execução de tarefas MapReduce, execução de scripts Pig, execução de consultas Hive, entre outras, permitindo que os usuários coordenem e agendem facilmente a execução de tarefas no Hadoop. Ele fornece uma interface intuitiva para definir fluxos de trabalho e oferece recursos avançados, como retentativas de tarefas, agendamento baseado em tempo e integração com outras ferramentas do ecossistema Hadoop.
ZooKeeper: serviço de coordenação e sincronização
O ZooKeeper é um serviço de coordenação e sincronização do ecossistema Hadoop. Ele fornece um ambiente confiável para coordenar e sincronizar as atividades distribuídas em um cluster Hadoop. O ZooKeeper permite que os aplicativos distribuídos compartilhem informações, coordenem suas atividades e lidem com situações de falha. Ele oferece recursos como eleição de líderes, bloqueios distribuídos, notificações assíncronas e gerenciamento de configurações, fornecendo uma base sólida para a construção de aplicativos distribuídos robustos no ecossistema Hadoop.
Apache Spark: processamento de dados em memória
O Apache Spark é um poderoso componente do ecossistema Hadoop que oferece um mecanismo de processamento de dados em memória. Ele fornece uma interface de programação simples e rica para a execução de análises de dados distribuídas em larga escala. O Spark oferece suporte a várias linguagens de programação, como Java, Scala e Python, e fornece bibliotecas extensas para processamento de dados em lotes, processamento de fluxo, aprendizado de máquina e processamento de gráficos. O Spark é conhecido por sua velocidade e eficiência, especialmente para cargas de trabalho que exigem iterações rápidas e acesso rápido aos dados.
Conclusão
O Apache Hadoop se estabeleceu como uma das principais soluções para o processamento de Big Data, oferecendo escalabilidade, tolerância a falhas e recursos avançados para lidar com grandes volumes de dados. À medida que o mundo do Big Data continua a evoluir, o Hadoop desempenhará um papel crucial na capacidade de organizações e pesquisadores de aproveitar ao máximo o potencial dos dados em larga escala.




